Elo 排名系統¶
Elo 排名系統最初為象棋等雙人遊戲開發,旨在根據玩家(或模型)在對抗賽中的表現,提供動態的定量技能水平度量。通過在每場比賽後持續更新評級,Elo 系統反映了模型的最新能力,從而實現更準確的比較。
在 OLPS 的背景下,比較不同方法在各種數據集上的性能可能會很具挑戰性。考慮到某種方法在一個數據集上表現出色,但在另一個數據集上表現不佳,因此建立一種排名方法以比較不同數據集上的方法變得至關重要。
最初,我們創建了一個簡單的線性更新版本的 Elo 排名系統。更新兩個競爭模型 \(a\) 和 \(b\) 的評級的核心公式如下:
初始化評級:
允許每種方法(不包括事後方法 BEST 和 BCRP)在相同的數據集和指標上以成對的方式相互競爭:
>>> print(battles)
model_a model_b dataset metric winner
0 Market UCRP NYSE(O) CW model_b
1 Market UCRP NYSE(O) APY model_b
2 Market UCRP NYSE(O) SR model_b
3 Market UP NYSE(O) CW model_b
4 Market UP NYSE(O) APY model_b
... ... ... ... ... ...
13657 CW-OGD GRW CRYPTO APY model_b
13658 CW-OGD GRW CRYPTO SR model_b
13659 CW-OGD WAAS CRYPTO CW model_b
13660 CW-OGD WAAS CRYPTO APY model_b
13661 CW-OGD WAAS CRYPTO SR model_b
[13662 rows x 5 columns]
對於模型 \(a\) 和 \(b\) 之間的每場較量,計算預期得分:
其中 \(R_a\) 和 \(R_b\) 分別是模型 \(a\) 和 \(b\) 的當前評級,而 \(S=400\) 是我們設定的縮放因子。
確定實際得分:
如果模型 \(a\) 勝出: \(S_a = 1\)
如果模型 \(b\) 勝出: \(S_a = 0\)
如果是平局: \(S_a = 0.5\)
根據比賽結果更新評級:
其中 \(K\) 是 Elo 更新因子,\(R'_a\) 和 \(R'_b\) 是戰鬥後的更新評級。
初步實現的詳細代碼如下:
>>> def compute_elo(battles, K=4, SCALE=400, BASE=10, INIT_RATING=1000):
>>> rating = defaultdict(lambda: INIT_RATING)
>>> for rd, model_a, model_b, winner in battles[['model_a', 'model_b', 'winner']].itertuples():
>>> ra = rating[model_a]
>>> rb = rating[model_b]
>>> ea = 1 / (1 + BASE ** ((rb - ra) / SCALE))
>>> eb = 1 / (1 + BASE ** ((ra - rb) / SCALE))
>>> if winner == "model_a":
>>> sa = 1
>>> elif winner == "model_b":
>>> sa = 0
>>> elif winner == "tie" or winner == "tie (bothbad)":
>>> sa = 0.5
>>> else:
>>> raise Exception(f"unexpected vote {winner}")
>>> rating[model_a] += K * (sa - ea)
>>> rating[model_b] += K * (1 - sa - eb)
>>> return rating
然而,我們觀察到即使使用較小的 Elo 更新因子 (\(K\)),排名系統對戰鬥順序也很敏感。為了解決這個問題,我們採用了自助法來增強 Elo 排名系統,使我們能夠獲得評級的置信區間。關鍵步驟如下:
我們在戰鬥數據的自助樣本上多次運行 compute_elo 函數(例如,1,000 次)。
這樣我們就得到了每個模型的 Elo 評級分佈,然後可以用來計算中位數和置信區間等穩健統計數據。
最終的 Elo 排名基於自助樣本中的中位數 Elo 評級。
該過程在以下代碼中實現:
>>> def get_bootstrap_result(battles, func_compute_elo, num_round):
>>> rows = []
>>> for i in tqdm(range(num_round), desc="bootstrap"):
>>> rows.append(func_compute_elo(battles.sample(frac=1.0, replace=True)))
>>> df = pd.DataFrame(rows)
>>> return df[df.median().sort_values(ascending=False).index]
>>> BOOTSTRAP_ROUNDS = 1000
>>> np.random.seed(config["MANUAL_SEED"])
>>> bootstrap_elo_lu = get_bootstrap_result(battles, compute_elo, BOOTSTRAP_ROUNDS)
>>> bootstrap_lu_median = bootstrap_elo_lu.median().reset_index().set_axis(["model", "Elo rating"], axis=1)
>>> bootstrap_lu_median["Elo rating"] = (bootstrap_lu_median["Elo rating"] + 0.5).astype(int)
這種方法提供了一種比較不同 OLPS 方法的原則。
盈利能力的 Elo 排名結果¶
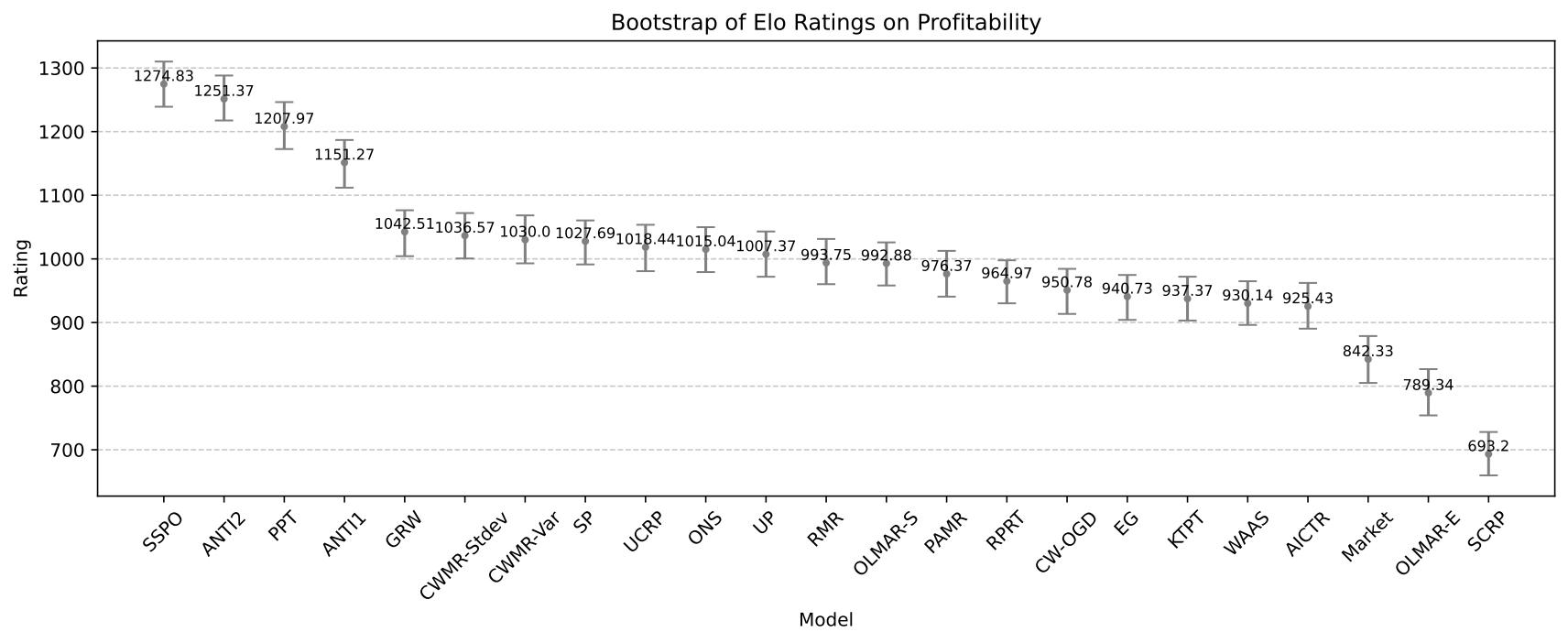
盈利能力的 Elo 評級自助估計¶
模型 |
Elo 評級 |
排名 |
|---|---|---|
SSPO |
1275 |
1 |
ANTI2 |
1251 |
2 |
PPT |
1208 |
3 |
ANTI1 |
1151 |
4 |
GRW |
1043 |
5 |
CWMR-Stdev |
1037 |
6 |
CWMR-Var |
1030 |
7 |
SP |
1028 |
8 |
UCRP |
1018 |
9 |
ONS |
1015 |
10 |
UP |
1007 |
11 |
RMR |
994 |
12 |
OLMAR-S |
993 |
13 |
PAMR |
976 |
14 |
RPRT |
965 |
15 |
CW-OGD |
951 |
16 |
EG |
941 |
17 |
KTPT |
937 |
18 |
WAAS |
930 |
19 |
AICTR |
925 |
20 |
Market |
842 |
21 |
OLMAR-E |
789 |
22 |
SCRP |
693 |
23 |
風險抵禦能力的 Elo 排名結果¶
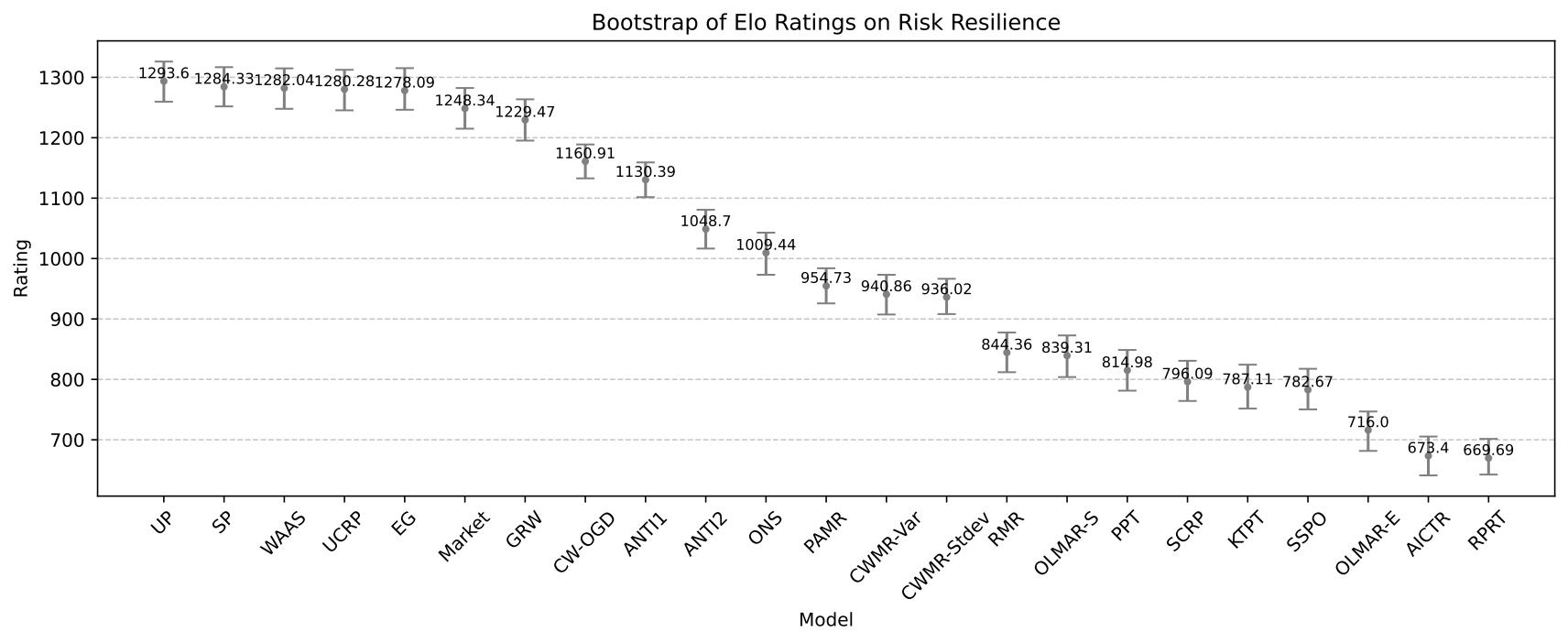
風險抵禦能力的 Elo 評級自助估計¶
模型 |
Elo 評級 |
排名 |
|---|---|---|
UP |
1294 |
1 |
SP |
1284 |
2 |
WAAS |
1282 |
3 |
UCRP |
1280 |
4 |
EG |
1278 |
5 |
Market |
1248 |
6 |
GRW |
1229 |
7 |
CW-OGD |
1161 |
8 |
ANTI1 |
1130 |
9 |
ANTI2 |
1049 |
10 |
ONS |
1009 |
11 |
PAMR |
955 |
12 |
CWMR-Var |
941 |
13 |
CWMR-Stdev |
936 |
14 |
RMR |
844 |
15 |
OLMAR-S |
839 |
16 |
PPT |
815 |
17 |
SCRP |
796 |
18 |
KTPT |
787 |
19 |
SSPO |
783 |
20 |
OLMAR-E |
716 |
21 |
AICTR |
673 |
22 |
RPRT |
670 |
23 |
實用性的 Elo 排名結果¶
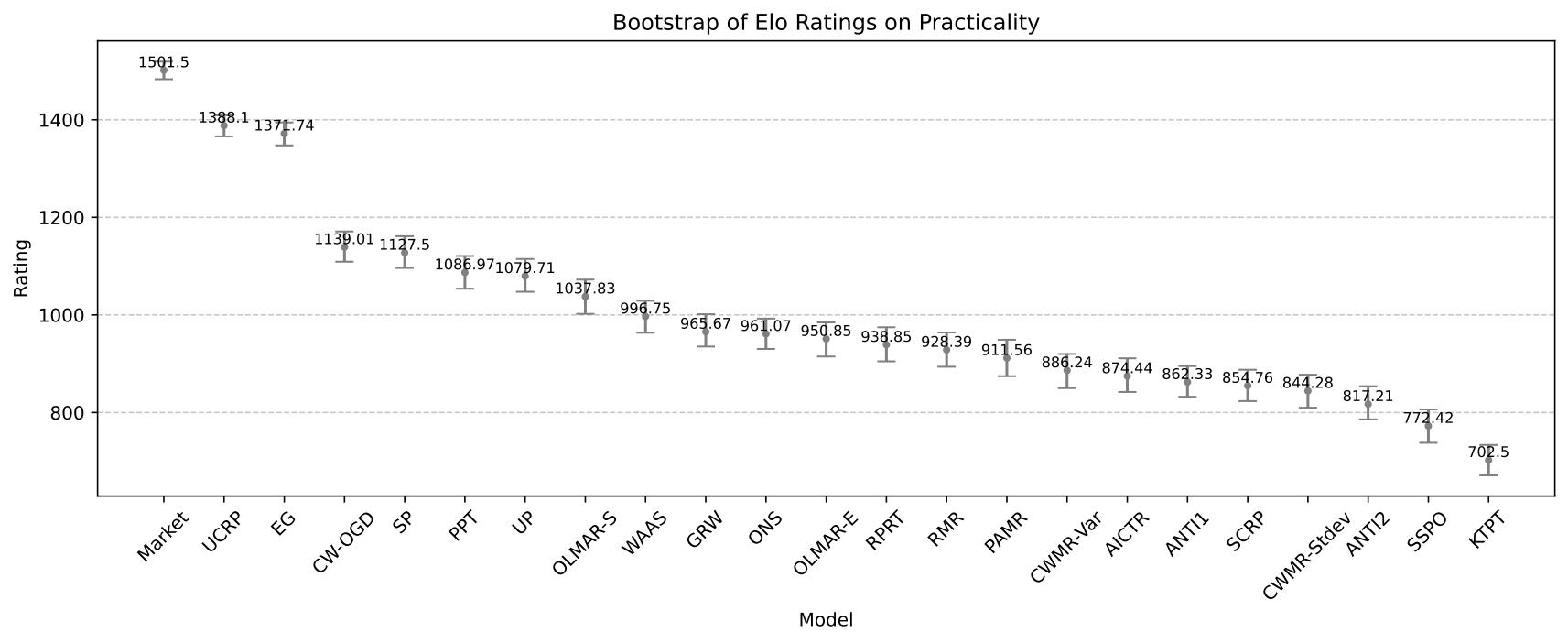
盈利能力的 Elo 評級自助估計¶
模型 |
Elo 評級 |
排名 |
|---|---|---|
Market |
1502 |
1 |
UCRP |
1388 |
2 |
EG |
1372 |
3 |
CW-OGD |
1139 |
4 |
SP |
1128 |
5 |
PPT |
1087 |
6 |
UP |
1080 |
7 |
OLMAR-S |
1038 |
8 |
WAAS |
997 |
9 |
GRW |
966 |
10 |
ONS |
961 |
11 |
OLMAR-E |
951 |
12 |
RPRT |
939 |
13 |
RMR |
928 |
14 |
PAMR |
912 |
15 |
CWMR-Var |
886 |
16 |
AICTR |
874 |
17 |
ANTI1 |
862 |
18 |
SCRP |
855 |
19 |
CWMR-Stdev |
844 |
20 |
ANTI2 |
817 |
21 |
SSPO |
772 |
22 |
KTPT |
703 |
23 |