预构建模型¶
参见
有关更多详细信息,请参见 model_layer。
作为一个软件包,FinOL 的一部分创新是在其模型层中预先实现的模型。这些预构建的模型为数据驱动的 OLPS 领域的研究人员提供了显著的优势,为他们提供了坚实的基础。通过利用这些模型,研究人员可以简化项目的初始阶段,避免从头构建复杂模型,从而节省宝贵的时间和资源。
时间序列表示模型¶
FinOL 中的时间序列表示模型旨在解决数据驱动的 OLPS 中顺序数据的独特挑战。这些模型专门设计用于处理顺序输入,确保准确捕捉和分析金融时间序列数据中固有的时间依赖性。通过利用这些模型,研究人员可以深入洞察市场趋势、价格波动及其他影响数据驱动 OLPS 任务的关键因素。
AlphaPortfolio¶
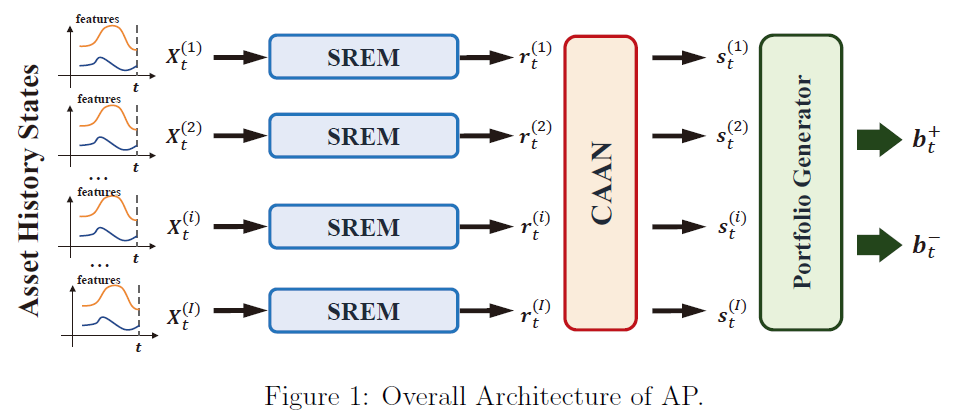
AlphaPortfolio 的整体框架¶
- 描述:
AlphaPortfolio 模型是一个基于 Transformer 的资产评分和投资组合选择模型。
- 基本思想:
利用注意力机制根据资产的历史表现进行评分。
- 模型构造:
- 优点:
资产评分的高准确性;通过经济蒸馏提供的可解释结果。
- 缺点:
计算密集型;需要仔细调整超参数。
- 细节:
AlphaPortfolio 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。AlphaPortfolio 模型的最终输出是形状为(batch_size, num_assets)的张量,表示对应资产的预测评分。
有关更多详细信息,请参阅论文 AlphaPortfolio: Direct Construction through Reinforcement Learning and Interpretable AI。
Hyper-parameter |
Choice |
Hyper-parameter |
Choice |
|---|---|---|---|
Embedding dimension |
256 |
Optimizer |
SGD |
Feed-forward network |
1021 |
Learning rate |
0.0001 |
Number of multi-head |
4 |
Dropout ratio |
0.2 |
Number of TE layer |
1 |
Training epochs |
30 |
AlphaStock¶
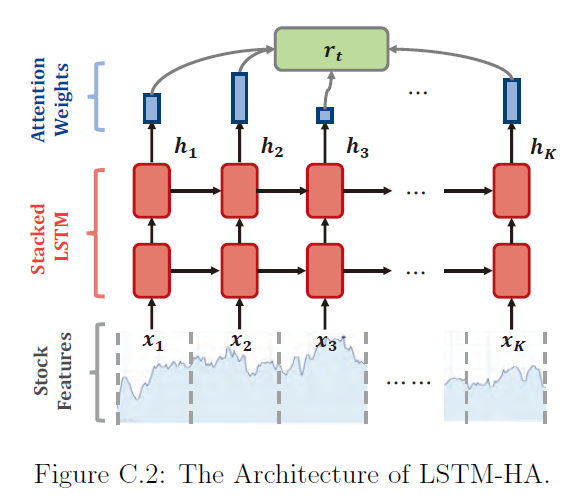
AlphaStock 的关键组件¶
- 描述:
AlphaStock 模型是一个基于 LSTM 的资产评分和投资组合选择模型。
- 基本思想:
利用 LSTM 捕捉资产数据中的顺序依赖和全局依赖。
- 模型构造:
- 优点:
对时间序列数据有效;能够随时间学习复杂模式。
- 缺点:
可能会出现过拟合。
- 细节:
AlphaStock 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。AlphaStock 模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
有关更多详细信息,请参阅论文 AlphaStock: A Buying-Winners-and-Selling-Losers Investment Strategy using Interpretable Deep Reinforcement Attention Networks。
DNN¶
- 描述:
用于资产评分和投资组合选择的深度神经网络模型。
- 基本思想:
实现多个全连接层以从输入特征中学习表示。
- 模型构造:
- 优点:
灵活的架构。
- 缺点:
没有正则化的过拟合风险。
- 细节:
DNN 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
GRU¶
- 描述:
用于资产评分和投资组合选择的门控循环单元模型。
- 基本思想:
类似于 LSTM,但具有更简单的架构,专注于捕捉顺序依赖性。
- 模型构造:
- 优点:
比 LSTM 计算需求低;训练时间更快。
- 缺点:
可能无法像 LSTM 一样有效捕捉长期依赖性。
- 细节:
GRU 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
LSRE-CAAN¶
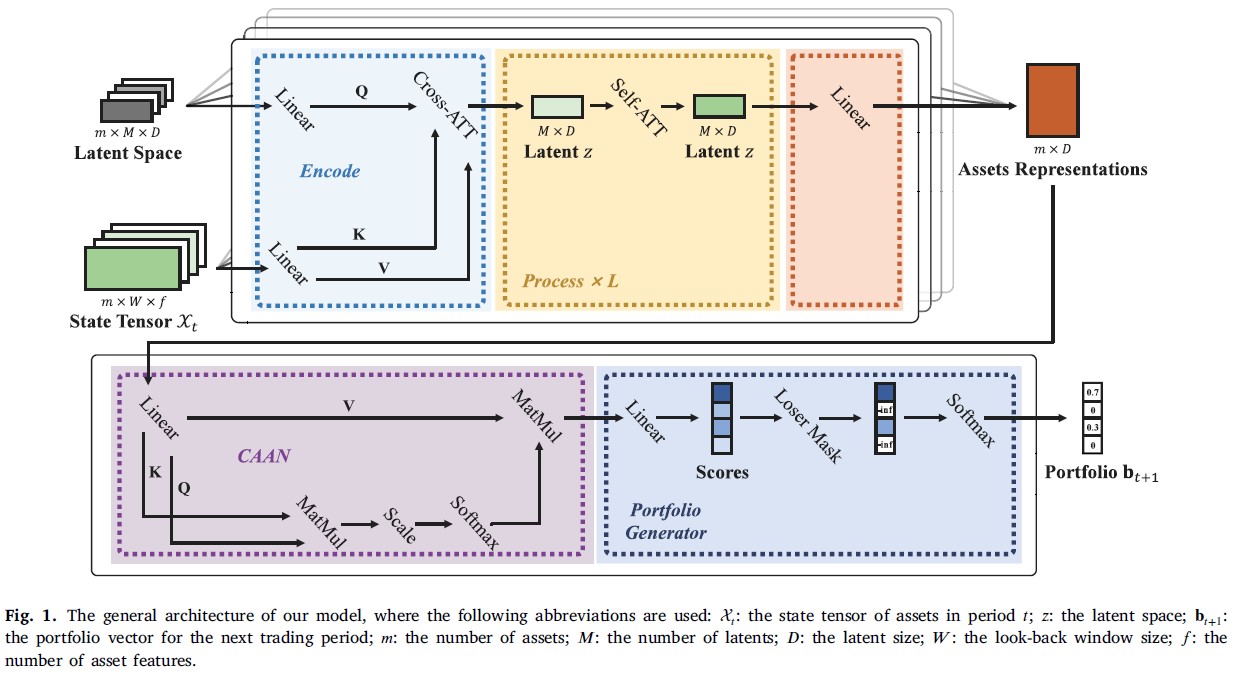
LSRE-CAAN 的整体框架¶
- 描述:
LSRE-CAAN 模型是一个基于 Transformer 的资产评分和投资组合选择模型。
- 基本思想:
结合长序列表示和注意力机制,以解决 AlphaPortfolio 中的效率问题。
- 模型构造:
- 优点:
在处理长序列方面高效;强大的注意力机制。
- 缺点:
缺乏理论保证。
- 细节:
LSRE-CAAN 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
有关更多详细信息,请参阅论文 Online portfolio management via deep reinforcement learning with high-frequency data。
Hyper-parameter |
Choice |
描述 |
|---|---|---|
Depth of net (L) |
1 |
The number of process layers in LSRE. |
Number of latents (M) |
1 |
The number of latents. |
Latent dimension (D) |
32 |
The size of the latent space. |
Number of cross-heads |
1 |
The number of heads for cross-attention. |
Number of latent-heads |
1 |
The number of heads for latent self-attention. |
Cross-attention dimension |
64 |
The number of dimensions per cross-attention head. |
Self-attention dimension |
32 |
The number of dimensions per latent self-attention head. |
Dropout ratio |
None |
No dropout is used following Jaegle et al. (2022). |
Embedding dimension |
None |
No Embedding layer is used, as illustrated in Section 4.1. |
Optimizer |
LAMB |
An optimizer specifically designed for Transformer-based models. |
Learning rate |
0.001 |
Parameter of the LAMB optimizer. |
Weight decay rate |
0.01 |
Parameter of the LAMB optimizer. |
Training steps |
104 |
Training times. |
Episode length (T) |
50 |
The length of an episode. |
G |
m/2 |
Half of the assets are identified as winners. |
W |
100 |
The look-back window size. |
LSTM¶
- 描述:
用于资产评分和投资组合选择的长短期记忆模型。
- 基本思想:
旨在长时间记忆信息,适合时间序列数据。
- 模型构造:
- 优点:
非常适合捕捉时间依赖性;在时间序列领域广泛使用。
- 缺点:
比传统 RNN 更复杂;计算开销可能较大。
- 细节:
LSTM 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
RNN¶
- 描述:
用于资产评分和投资组合选择的递归神经网络模型。
- 基本思想:
通过保持一个隐状态来处理数据序列,该隐状态捕捉来自先前输入的信息。
- 模型构造:
- 优点:
架构简单;对短期依赖有效。
- 缺点:
在长期依赖方面表现较差;可能会遭遇梯度消失问题。
- 细节:
RNN 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
TCN¶
- 描述:
用于资产评分和投资组合选择的时序卷积网络模型。
- 基本思想:
利用卷积层捕捉序列中的时间依赖性。
- 模型构造:
- 优点:
能够处理长距离依赖;支持并行训练。
- 缺点:
可能需要仔细设计网络架构;比 RNN 的可解释性差。
- 细节:
TCN 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
Transformer¶
- 描述:
用于资产评分和投资组合选择的 Transformer 模型。
- 基本思想:
采用自注意力机制并行处理序列。
- 模型构造:
- 优点:
对于广泛的任务非常有效;能够捕捉复杂关系。
- 缺点:
需要大量计算资源。
- 细节:
Transformer 模型接受形状为
(batch_size, num_assets, num_features_augmented)的输入张量x,其中num_features_augmented表示每个资产的特征数量(包括任何预处理或增强的特征)。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
图像表示模型¶
除了时间序列数据,FinOL 还提供图像表示模型。这些模型旨在从金融图像中提取有意义的表示,例如图表、图形和其他视觉数据。通过这样做,它使研究人员能够利用视觉格式中包含的大量信息,这对模式识别、趋势分析等任务至关重要。将此模型纳入 FinOL 进一步巩固了其作为数据驱动 OLPS 研究的多功能工具的地位。
CNN¶
- 描述:
用于资产评分和投资组合选择的卷积神经网络模型。
- 基本思想:
应用卷积层从资产的图像中提取特征。
- 模型构造:
- 优点:
对图像分类和特征提取有效。
- 缺点:
需要大量计算资源。
- 细节:
CNN 模型接受形状为
(batch_size, num_assets, height, width)的输入张量x,其中height和width是每个资产的图像尺寸。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
CNN-JF¶
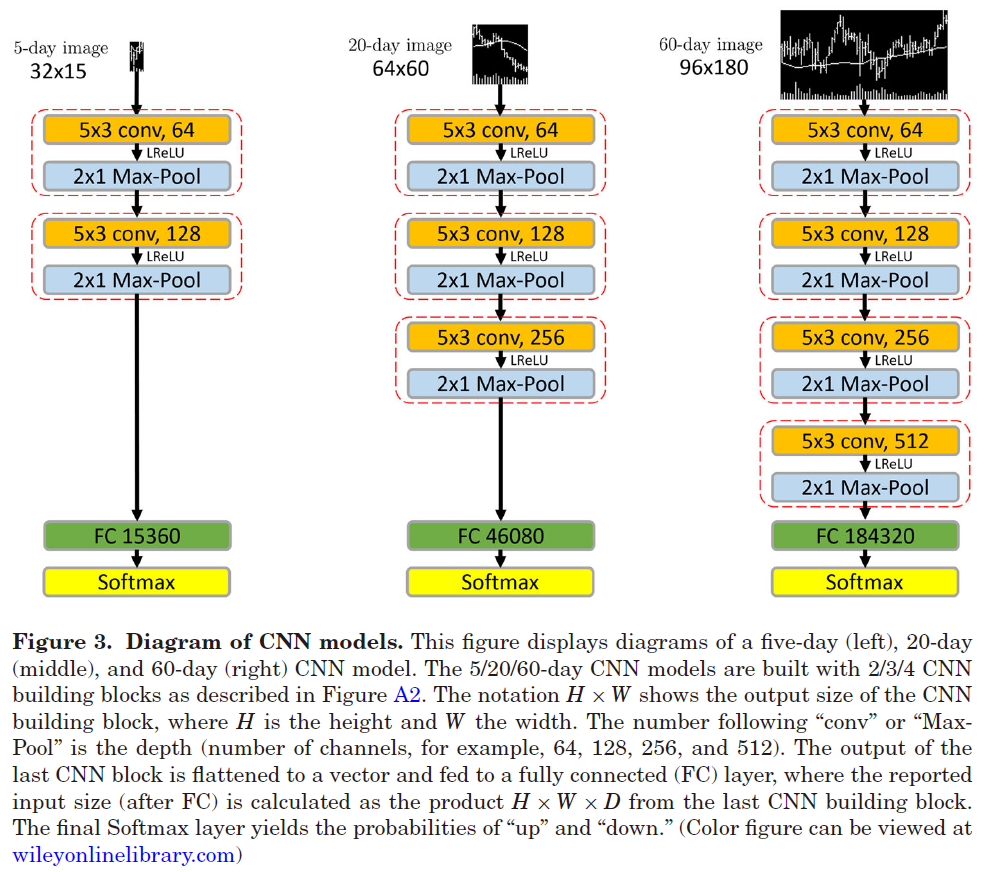
CNN-JF 的整体框架¶
- 描述:
CNN-JF 模型是一个基于 CNN 的资产评分和投资组合选择模型。它利用 CNN 来分析以图像形式表示的历史股票价格数据。
- 基本思想:
利用 CNN 架构捕捉以视觉方式表示的金融时间序列中的模式。
- 模型构造:
- 优点:
结合视觉数据分析和金融建模的优势。
- 缺点:
需要大量计算资源。
- 细节:
CNN-JF 模型接受形状为
(batch_size, num_assets, height, width)的输入张量x,其中height和width是每个资产的图像尺寸。该模型的最终输出是形状为(batch_size, num_assets)的张量,每个元素表示对应资产的预测评分。
有关更多详细信息,请参阅论文 (Re-)Imag(in)ing Price Trends。
Hyper-parameter |
Choice |
Hyper-parameter |
Choice |
|---|---|---|---|
Kernel Size Height |
5 |
Kernel Size Width |
3 |
Stride Height |
3 |
Stride Width |
1 |
Dilation Height |
2 |
Dilation Width |
1 |
Padding Height |
12 |
Padding Width |
1 |
Dropout Rate |
0.5 |